Benchmark different kernel implementations¶
You can benchmark different gate implementations inside the project.
$ make gbenchmark
$ cd BuildGBench
Then you can benchmark all gate operations in all kernels by running the script.
$ ./benchmarks/benchmark_all.sh
The results will be recorded in bench_result.json file.
You can then plot the results for a specific gate with
$ ./benchmarks/plot_gate_benchmark.py ./bench_result.json
It will create a plot for each gate operation comparing performance of kernels and floating point types. The plots can be found in plots subdirectory.
One can also choose a specific datatype by providing an option:
$ ./benchmarks/plot_gate_benchmark.py --precision float ./bench_result.json # Results for std::complex<float>
$ ./benchmarks/plot_gate_benchmark.py --precision double ./bench_result.json # Results for std::complex<double>
Currently, we have two different kernels in Lightning Qubit named PI and LM. For difference between two kernels, see the documents Pennylane::Gates::GateImplementationsPI and Pennylane::Gates::GateImplementationsLM.
Here are some example plots:
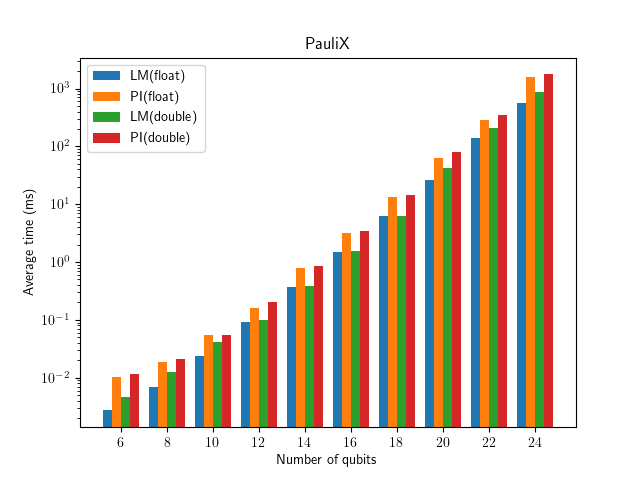
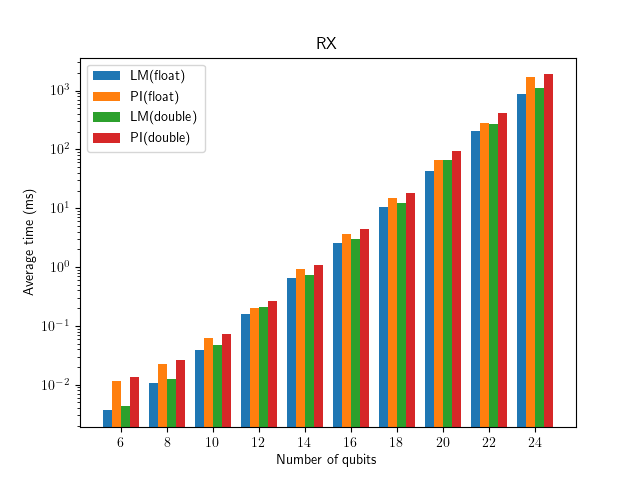
benchmark
Download Python script
Download Notebook
View on GitHub